
Motivation and Introduction
As part of the software team at Nevados we are building an operations and monitoring platform for the Nevados All Terrain Tracker®. A solar tracker is a device that orients a solar panel toward the sun. Every solar tracker constantly sends status information and readings, such as the current angle, temperature, voltages, etc. to our platform and we need to store this information for analysis and visualization. If the tracker is configured to send data every 5 seconds, we have 17,280 data points per tracker per day, 518,400 data points per tracker per month. That sums up a lot of information. This kind of data is called “time-series data” and as for all complex problems in software, there are several solutions (Time Series Databases) for it. The most famous ones being InfluxDB and TimescaleDB. For our platform, we decided to work with TDEngine, a relatively new product that is optimized for IoT applications and works with the SQL query language.
There were several arguments for this decision: TDEngine
- is open source
- is optimized for IoT applications
- uses SQL, which is a language we are familiar with
- is available as a managed service and we can focus on building our application
- is easy to run locally via Docker
In this article, we’ll go through the setup of a TDEngine database and tables and how to craft a GraphQL schema that allows us to query the data from various clients and applications.
Getting started with TDEngine
The easiest way to get started with TDEngine is to use their cloud service. Go to the TDEngine and create an account. They have a few public databases we can use, which is great to put together a demo or experiment with queries.
If you want to run TDEngine locally, you can use the Docker image and Telegraf to retrieve data from various sources and send them to the database, such as system information, ping statistics etc.
version: '3.9'
services:
tdengine:
restart: always
image: tdengine/tdengine:latest
hostname: tdengine
container_name: tdengine
ports:
- 6030:6030
- 6041:6041
- 6043-6049:6043-6049
- 6043-6049:6043-6049/udp
volumes:
- data:/var/lib/taos
telegraf:
image: telegraf:latest
links:
- tdengine
env_file: .env
volumes:
- ./telegraf.conf:/etc/telegraf/telegraf.confCheck out the official documentation for the Telegraf configuration and the TDEngine documentation on Telegraf. In short, this would look something like this to connect to an MQTT topic:
[agent]
interval = "5s"
round_interval = true
omit_hostname = true
[[processors.printer]]
[[outputs.http]]
url = "http://127.0.0.1:6041/influxdb/v1/write?db=telegraf"
method = "POST"
timeout = "5s"
username = "root"
password = "taosdata"
data_format = "influx"
[[inputs.mqtt_consumer]]
topics = [
"devices/+/trackers",
]Instead of setting everything up locally and waiting for the database to fill with information, we’ll use the public database for this article, which contains ship movements from the 5 major US ports.
Using TDEngine with public ship movement data
By default, the tables in TDEngine have an implicit schema, which means the schema adapts to the data that is written to the database. This is great for bootstrapping, but eventually, we want to switch to an explicit schema to avoid issues with incoming data. One thing that takes a little time to get used to is their concept of Super Tables (“STable” for short). In TDEngine there are tags (keys) and columns (data). For each key combination, a “table” is created. All tables are grouped in the STable.
Looking at the vessel database, they have one STable called ais_data which
contains a lot of tables. Usually, we do not want to query on a per-table basis,
but always use the STable to get accumulated data from all tables.
TDEngine has a function DESCRIBE which allows us to inspect the schema of a
table or STable. The ais_data has the following schema:

The STable has two keys and six data columns. The keys are the mmsi and the
name. We can use regular SQL statements to query the data:
SELECT ts, name, latitude, longitude FROM vessel.ais_data LIMIT 100;
ts name latitude longitude
2023-08-11T22:07:02.419Z GERONIMO 37.921673 -122.40928
2023-08-11T22:21:48.985Z GERONIMO 37.921688 -122.40926
2023-08-11T22:25:08.784Z GERONIMO 37.92169 -122.40926
...Keep in mind that time-series data is usually very large, so we should always
limit the resultset. There are a few time-series specific functions that we can
use, like PARTITION BY which groups results by key and is useful to get the
latest update individual keys. For example:
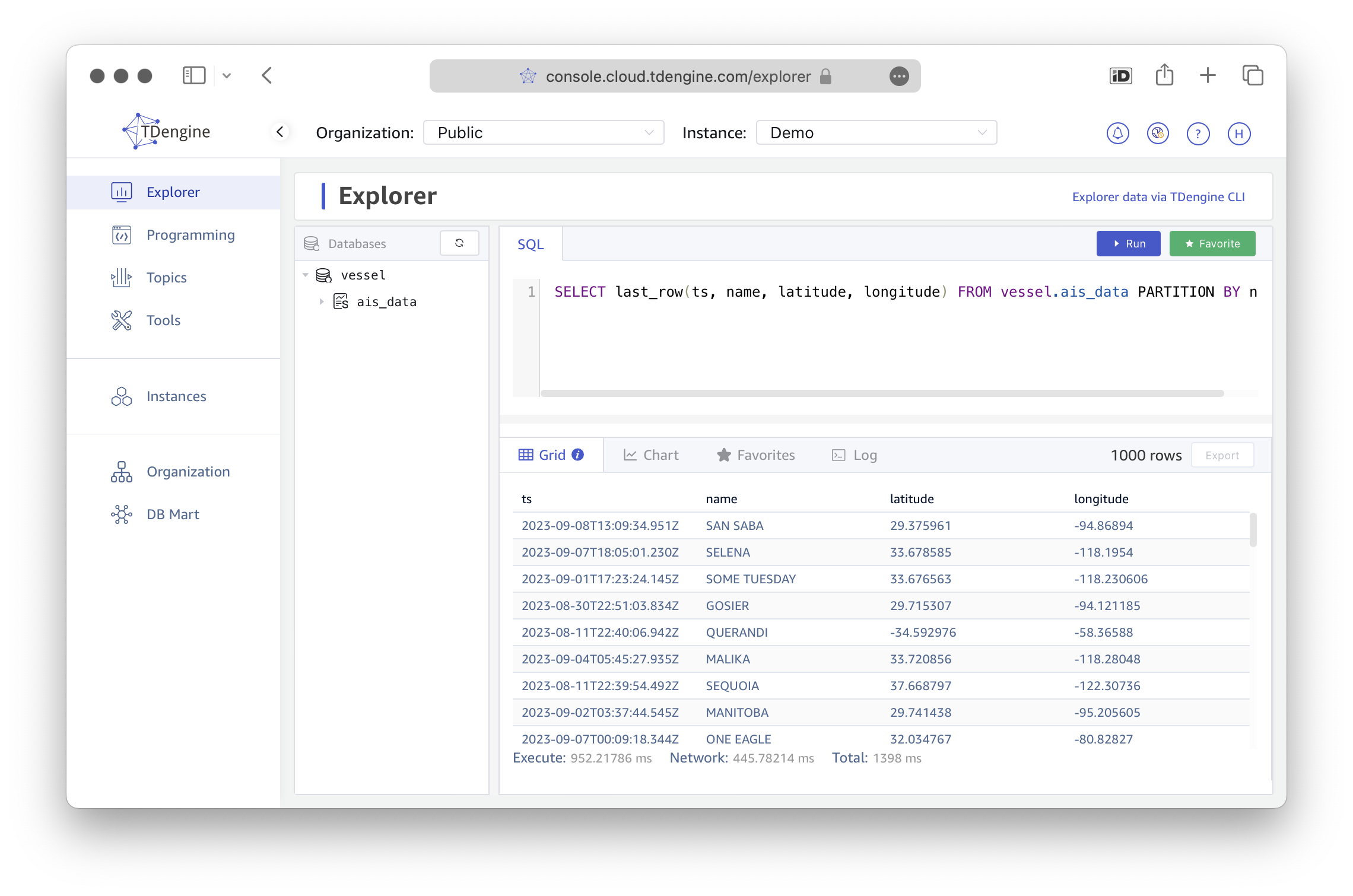
SELECT last_row(ts, name, latitude, longitude) FROM vessel.ais_data PARTITION BY name;
ts name latitude longitude
2023-09-08T13:09:34.951Z SAN SABA 29.375961 -94.86894
2023-09-07T18:05:01.230Z SELENA 33.678585 -118.1954
2023-09-01T17:23:24.145Z SOME TUESDAY 33.676563 -118.230606
...
I recommend reading their
SQL Documentation for more
examples. Before we move on, head to “Programming”, “Node.js” and retrieve your
TDENGINE_CLOUD_URL and TDENGINE_CLOUD_TOKEN variables.
GraphQL with Nexus.js, Fastify and Mercurius
GraphQL is pretty well known these days and there are lots of good articles about it. We chose the technology as we collect and process information from different sources and GraphQL allows us to transparently combine them into a single API.
We’ll use the amazing Fastify framework (by now the default choice for Node.js applications) and the Mercurius adapter. The teams of Mercurius and Fastify worked together for a seamless experience and it’s a great choice GraphQL APIs with a focus on performance. GraphQL Nexus is a tool to build/generate the schema and resolvers, so we do not have to write everything by hand.
There’s a bit of setup code etc. to be done, which I’ll skip here. You can find a full example on GitHub - tdengine-graphql-example.
I want to elaborate on two things in this article that are rather specific:
- the TDEngine Query library
- the GraphQL schema with Nexus
TDEngine Query library
TDEngine has a Node.js library that allows us to query the database. This makes it easy to connect and send queries, unfortunately the responses are a little difficult to work with. So we wrote a little wrapper:
'use strict'
import tdengine from '@tdengine/rest'
import { tdEngineToken, tdEngineUrl } from '../config.js'
import parseFields from 'graphql-parse-fields'
const { options: tdOptions, connect: tdConnect } = tdengine
tdOptions.query = { token: tdEngineToken }
tdOptions.url = tdEngineUrl
export default function TdEngine(log) {
this.log = log
const conn = tdConnect(tdOptions)
this.cursor = conn.cursor()
}
TdEngine.prototype.fetchData = async function fetchData(sql) {
this.log.debug('fetchData()')
this.log.debug(sql)
const result = await this.cursor.query(sql)
const data = result.getData()
const errorCode = result.getErrCode()
const columns = result.getMeta()
if (errorCode !== 0) {
this.log.error(`fetchData() error: ${result.getErrStr()}`)
throw new Error(result.getErrStr())
}
return data.map((r) => {
const res = {}
r.forEach((c, idx) => {
const columnName = columns[idx].columnName
.replace(/`/g, '')
.replace('last_row(', '')
.replace(')', '')
if (c !== null) {
res[columnName] = c
}
})
return res
})
}This returns a TDEngine object that can be passed into GraphQL context. We’ll
primarily be using the fetchData function where we can pass in a SQL query and
get the results back as an array of objects. TDEngine returns the metadata
(columns), errors and data separately. We’ll use the metadata to map the columns
into a regular list of objects. A special case here is the last_row function.
The columns are returned as last_row(ts), last_row(name) etc. and we want to
remove the last_row part so the attribute maps 1:1 to the GraphQL schema. This
is done in the columnName.replace part.
GraphQL Schema
Unfortunately there is no schema generator like
Postgraphile for TDEngine and we don’t want to write
and maintain a pure GraphQL schema, so we’ll use Nexus.js to help us with that.
We’ll start with two basic types: VesselMovement and Timestamp (which is a
scalar type). Timestamp and TDDate are two different types to display the
date as a timestamp or as a date string. This is useful for the client
application (and during development), as it can decide which format to use.
asNexusMethod allows us to use the type as a function in the VesselMovement
schema. We can resolve the TDDate right here in the type definition to use the
original ts timestamp value.
import { scalarType, objectType } from 'nexus'
export const Timestamp = scalarType({
name: 'Timestamp',
asNexusMethod: 'ts',
description: 'TDEngine Timestamp',
serialize(value) {
return new Date(value).getTime()
}
})
export const TDDate = scalarType({
name: 'TDDate',
asNexusMethod: 'tdDate',
description: 'TDEngine Timestamp as Date',
serialize(value) {
return new Date(value).toJSON()
}
})
export const VesselMovement = objectType({
name: 'VesselMovement',
definition(t) {
t.ts('ts')
t.tdDate('date', { resolve: (root) => root.ts })
t.string('mmsi')
t.string('name')
t.float('latitude')
t.float('longitude')
t.float('speed')
t.float('heading')
t.int('nav_status')
}
})For time-series types, we use the Movement or Series suffix for a clear
separation of relational and time-series types in the interface.
Now we can define the Query. We’ll start with a simple query to get the latest movements from TDEngine:
import { objectType } from 'nexus'
export const GenericQueries = objectType({
name: 'Query',
definition(t) {
t.list.field('latestMovements', {
type: 'VesselMovement',
resolve: async (root, args, { tdEngine }, info) => {
const fields = filterFields(info)
return tdEngine.fetchData(
`select last_row(${fields}) from vessel.ais_data partition by mmsi;`
)
}
})
}
})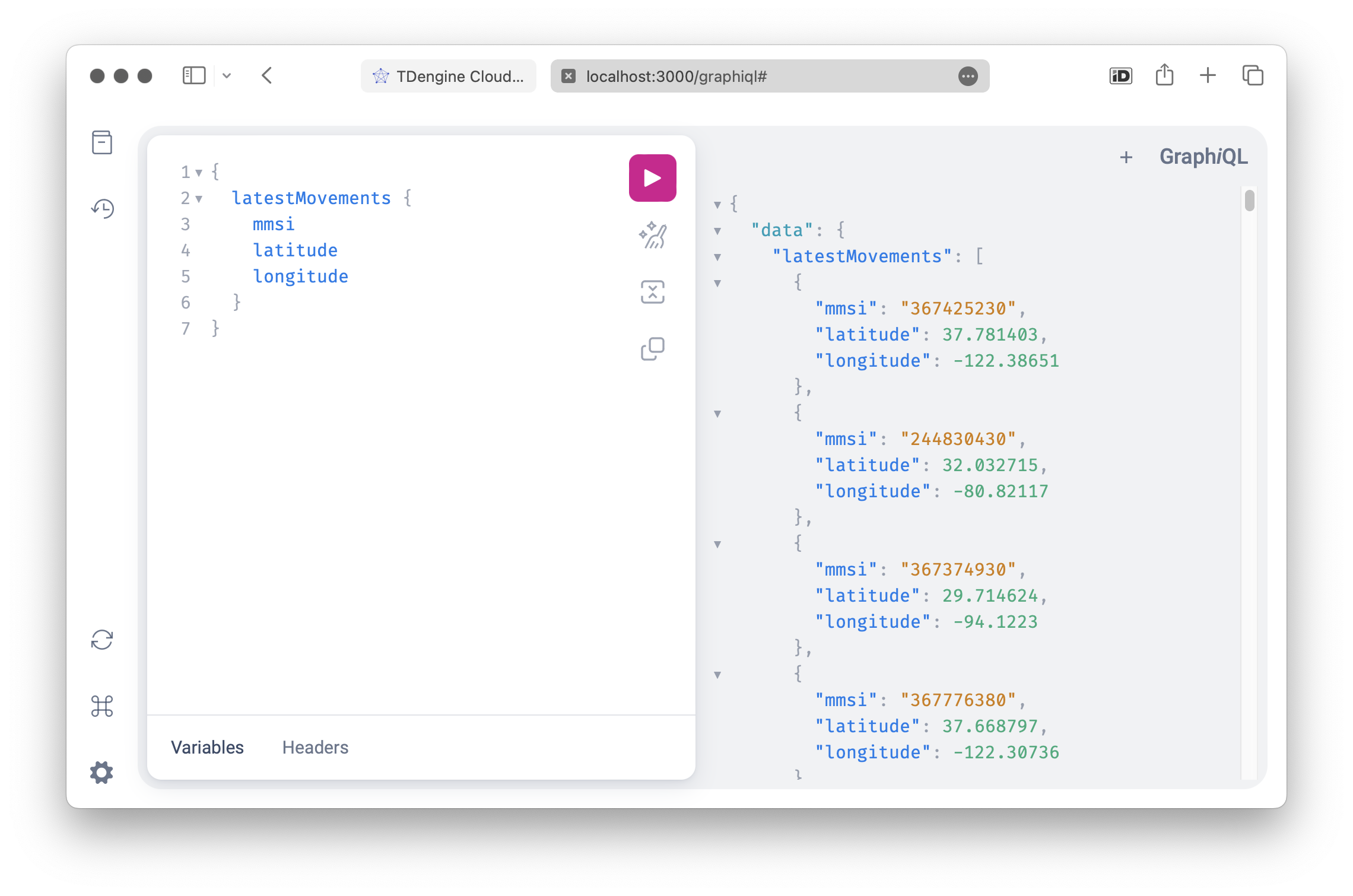
GraphiQL is a great tool to test the API
and explore the schema, you can enable it by passing graphiql.enabled = true
in Mercurius. With the query, we can see the latest movements of vessels grouped
by mmsi. Let’s go a little further though. One of the biggest advantages of
GraphQL is that is is a transparent layer to the client or application. We can
fetch data from multiple sources and combine them into the same schema.
Unfortunately, I wasn’t able to find an easy/free API with extensive vessel
information. There is
Sinay, but they only
provide the name, mmsi and imo in their Vessel response (which we already
have in TDEngine). For the sake of the example, we assume we do not have the
name in our database and we need to retrieve it from Sinay. With the imo we
could also query CO2 emissions for a vessel or another API could be used to
retrieve an image, the flag or other information, all of which can be combined
in the Vessel type.
export const Vessel = objectType({
name: 'Vessel',
definition(t) {
t.string('mmsi')
t.string('name')
t.nullable.string('imo')
t.list.field('movements', { type: 'VesselMovement' })
}
})As you can see here, we can include a list field movements with the
time-series data from TDEngine. We’ll add another query to fetch the vessel
information and the resolver allows us to combine the data from TDEngine and
Sinay:
t.field('vessel', {
type: 'Vessel',
args: {
mmsi: 'String'
},
resolve: async (root, args, { tdEngine }, info) => {
const waiting = [
getVesselInformation(args.mmsi),
tdEngine.fetchData(
`select * from vessel.ais_data where mmsi = '${args.mmsi}' order by ts desc limit 10;`
)
]
const results = await Promise.all(waiting)
return {
...results[0][0],
movements: results[1]
}
}
})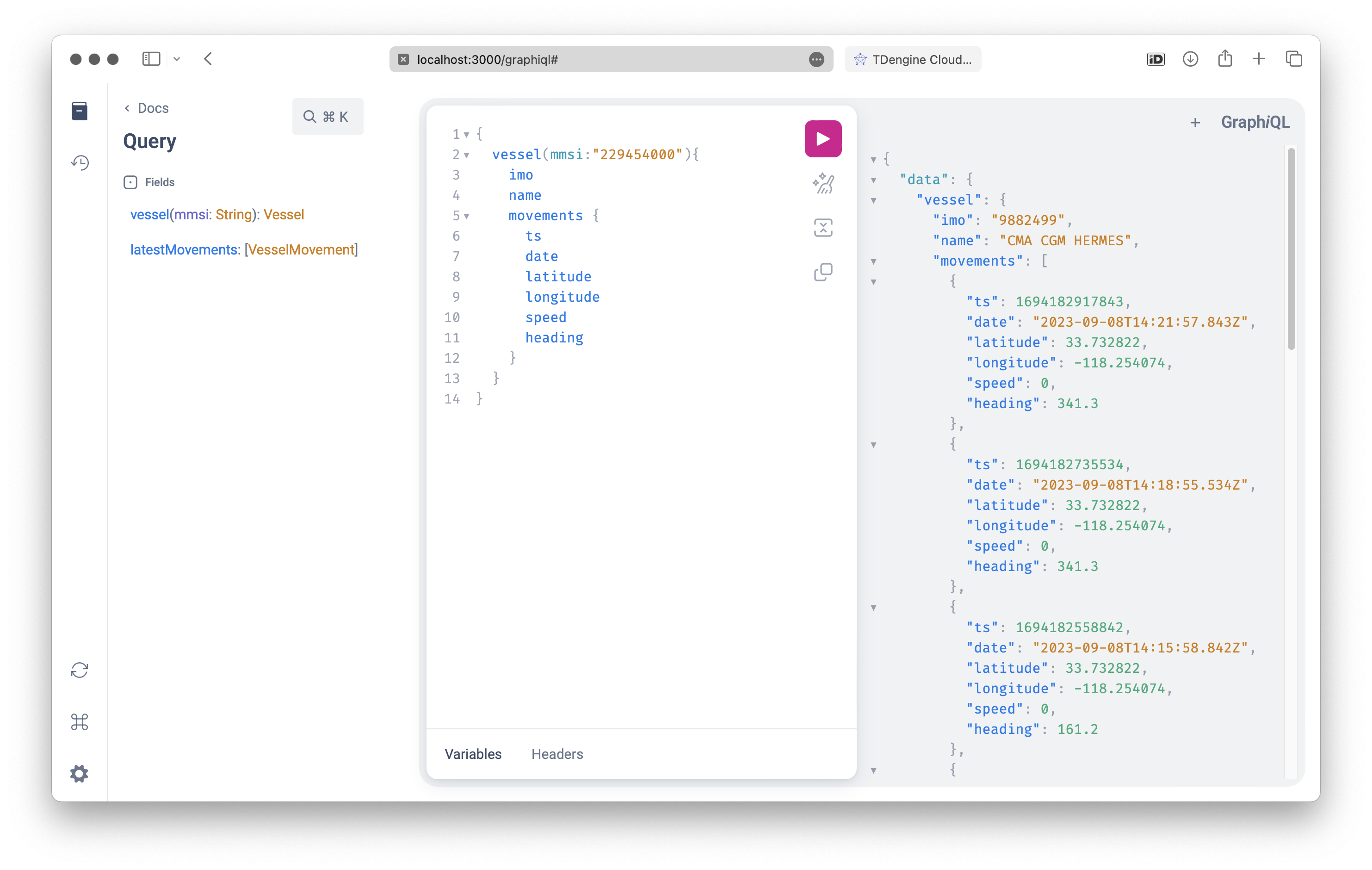
:tada: and here we have a working GraphQL API returning rows from TDEngine for a
specific vessel we requested. getVesselInformation() is a simple wrapper to
fetch data from Sinay. We’ll add the TDEngine results into the movements
attribute and GraphQL will take care of the rest and map everything to the
schema.
Note: SQL Injection
As with any SQL database, we need to be careful with user input. In the example
above we use the mmsi input directly, which makes this query vulnerable to SQL
injections. For the sake of the example, we’ll ignore this for now, but in “real
world” applications, we should always sanitize user input. There are several
small libraries around to sanitize strings, in most cases we only rely on
numbers (pagination, limit etc.) and enums (sort order), which GraphQL checks
for us.
Thanks to Dmitry Zaets for pointing this out!
Optimizations
There are a few things that go beyond the scope of this article, but I want to mention them briefly:
Pothos as spiritual successor to Nexus.js
When we started the project, Nexus.js was the best choice to generate our GraphQL schema. Although stable and somewhat feature-complete, it lacks maintenance and updates. There is a plugin-based GraphQL schema builder called Pothos which is a bit more modern and actively maintained. If you’re starting a new project, I probably recommend using Pothos instead of Nexus.js.
Thanks to Mo Sattler for pointing this out!
Field Resolvers
As you can see in the Vessel resolver above, both data sources are immediately
fetched and processed. This means if the query is only for the name, we still
fetch the movements for the response. And if the query is for the movements
only, we still fetch the name from Sinay and potentially pay for the request.
That’s a GraphQL anti-pattern and we can improve the performance by using the
field information to only fetch the data that is requested. Resolvers have the
field information as the fourth argument, but they’re pretty difficult to work
with. Instead, we can use
graphql-parse-fields to
get a simple object of the requested fields and adjust the resolver logic.
SQL Query Optimizations
In our example queries, we use select * to fetch all columns from the database
even if they’re not needed. This is obviously pretty bad and we can use the same
field parser to optimize the sql queries:
export function filterFields(info, context) {
const invalidFields = ['__typename', 'date']
const parsedFields = parseFields(info)
const fields = context ? parsedFields[context] : parsedFields
const filteredFields = Object.keys(fields).filter(
(f) => !invalidFields.includes(f)
)
return filteredFields.join(',')
}This function returns a comma-separated list of fields from the GraphQL info.
const fields = filterFields(info)
return tdEngine.fetchData(
`select last_row(${fields}) from vessel.ais_data partition by mmsi;`
)If we request ts, latitude and longitude, the query would look like this:
select last_row(ts, latitude, longitude) from vessel.ais_data partition by mmsi;With only a few columns in this table this might not matter much, but with more tables and complex queries, this can make a huge difference in application performance.
Time Series functions
TDEngine has some time-series specific extensions that should be used to improve performance. For example, to retrieve the latest entry, a traditional SQL query:
SELECT ts, name, latitude, longitude FROM vessel.ais_data order by ts desc limit 1;Takes 653ms to execute, while the “TDEngine” query takes only 145ms:
SELECT last_row(ts, name, latitude, longitude) FROM vessel.ais_data;There are configuration options for each table to optimize for last_row/first_row functions and other cache settings. I recommend reading the TDEngine documentation.
Conclusion
The simple version: In this article, we’ve set up a TDEngine time-series database and defined a GraphQL schema to allow client applications to connect & query data.
There’s a lot more to it. We have a boilerplate project to combine complex
time-series data with relational data in a transparent interface. At Nevados,
we’re using PostgreSQL as a primary database and retrieve time-series data the
same way as in the movement example above. This is a great way to combine data
from multiple sources in a single API. Another benefit is that the data is only
fetched when requested, which adds a lot of flexibility to the client
application. Last but not least, the GraphQL Schema works as a documentation and
contract, so we can easily tick the “API Documentation” box.
If you have any questions or comments, please reach out on BlueSky or join the discussion on GitHub.
